AI modely v roce 2026 na advokátní zkoušce: zlepšení přesnosti přidáním relevantního kontextu do úsporných modelů
Advokátní zkouška ČAK patří k nejobtížnějším profesním zkouškám v ČR. Porovnali jsme, jak se nejnovější AI modely zlepší přidáním relevantního kontextu – a výsledky ukazují dramatický rozdíl v přesnosti.
Úvod
Advokátní zkouška České advokátní komory (ČAK) je jednou z nejobtížnějších profesních zkoušek v České republice. Aktuálně se její písemná část skládá z vypracování odborné práce na zadané téma – uchazeči mají 6 hodin na sepsání řešení na noteboocích (podrobnosti na webu ČAK). Pro účely tohoto benchmarku jsme však využili dřívější formát zkoušky – písemný test se 100 otázkami typu A/B/C (právě 1 správná odpověď ze 3 možností, limit 90 minut, práh úspěšnosti 85/100). Tento formát je jediný, na kterém lze provést objektivní a automatizovaně vyhodnotitelný benchmark jazykových modelů – hodnocení volně psaných právních rozborů by vyžadovalo expertní posouzení a nebylo by reprodukovatelné a objektivní.
Zkouška pokrývá 5 okruhů:
- Ústavní a správní právo
- Trestní právo
- Občanské, rodinné a pracovní právo
- Obchodní právo
- Předpisy upravující poskytování právních služeb (advokacie)
V tomto výzkumu jsme testovali, jak si s těmito otázkami poradí nejlevnější (budget) jazykové modely od tří předních poskytovatelů AI – a především, zda jim přístup k české legislativě prostřednictvím technologie RAG výrazně pomůže.
Co je RAW a RAG model?
RAW (bez kontextu)
V režimu RAW model odpovídá výhradně na základě znalostí získaných při trénování. Nemá k dispozici žádné externí dokumenty ani právní předpisy. Odpovědi jsou tedy založeny na tom, co se model „naučil" z trénovacích dat. A to mohou být zastaralé, neúplné nebo nepřesné informace.
RAG (s kontextem legislativy)
V režimu RAG (Retrieval-Augmented Generation) model před odpovědí obdrží relevantní právní předpisy z databáze DirectCase. Systém na základě otázky automaticky vyhledá příslušné paragrafy, zákony a právní ustanovení a poskytne je modelu jako kontext. Model tak odpovídá s oporou v aktuálním znění skutečných právních předpisů.
Výhody RAG přístupu
Klíčovou výhodou RAG je, že model pracuje s reálnými, aktuálními právními dokumenty, nikoli se zapamatovanými fragmenty z trénování. To přináší:
- Aktuálnost – právní předpisy se mění, RAG vždy čerpá z aktuální databáze
- Přesnost citací – model může odkazovat na konkrétní paragrafy
- Snížení halucinací – model má k dispozici faktický podklad pro odpověď
- Nezávislost na trénovacích datech – i levnější model s menší znalostní bází může podávat kvalitní výkon
Testované modely a cenové srovnání
Testovali jsme nejlevnější dostupné modely od každého z hlavních poskytovatelů AI. Cílem bylo ověřit, zda i cenově nejdostupnější modely mohou s pomocí RAG dosáhnout přijatelného výkonu na náročné právní zkoušce.
| Claude Haiku 4.5 | GPT-5 mini | Gemini 3 Flash | |
|---|---|---|---|
| Poskytovatel | Anthropic | OpenAI | |
| Model ID | claude-haiku-4-5-20251001 |
gpt-5-mini-2025-08-07 |
gemini-3-flash-preview |
| Kontextové okno | 200K tokenů | 200K tokenů | 1M tokenů |
| Vstup / 1M tokenů | $1,00 | $0,25 | $0,50 |
| Výstup / 1M tokenů | $5,00 | $2,00 | $3,00 |
Jedná se o modely z kategorie „budget" – tedy nejlevnější varianty v nabídce každého poskytovatele. Ceny jsou uvedeny k březnu 2026.
Metodologie
Benchmark obsahuje celkem 462 otázek rozdělených do 5 okruhů:
| Okruh | Počet otázek |
|---|---|
| Ústavní a správní právo | 72 |
| Trestní právo | 79 |
| Občanské, rodinné a pracovní právo | 160 |
| Obchodní právo | 95 |
| Advokátní předpisy | 56 |
| Celkem | 462 |
Každý model byl testován ve dvou režimech:
- RAW – model obdržel pouze otázku a tři možnosti odpovědí
- RAG – model obdržel otázku, tři možnosti odpovědí a relevantní právní předpisy vyhledané v databázi DirectCase
Hranice úspěšnosti pro složení advokátní zkoušky je 85 %.
Výsledky
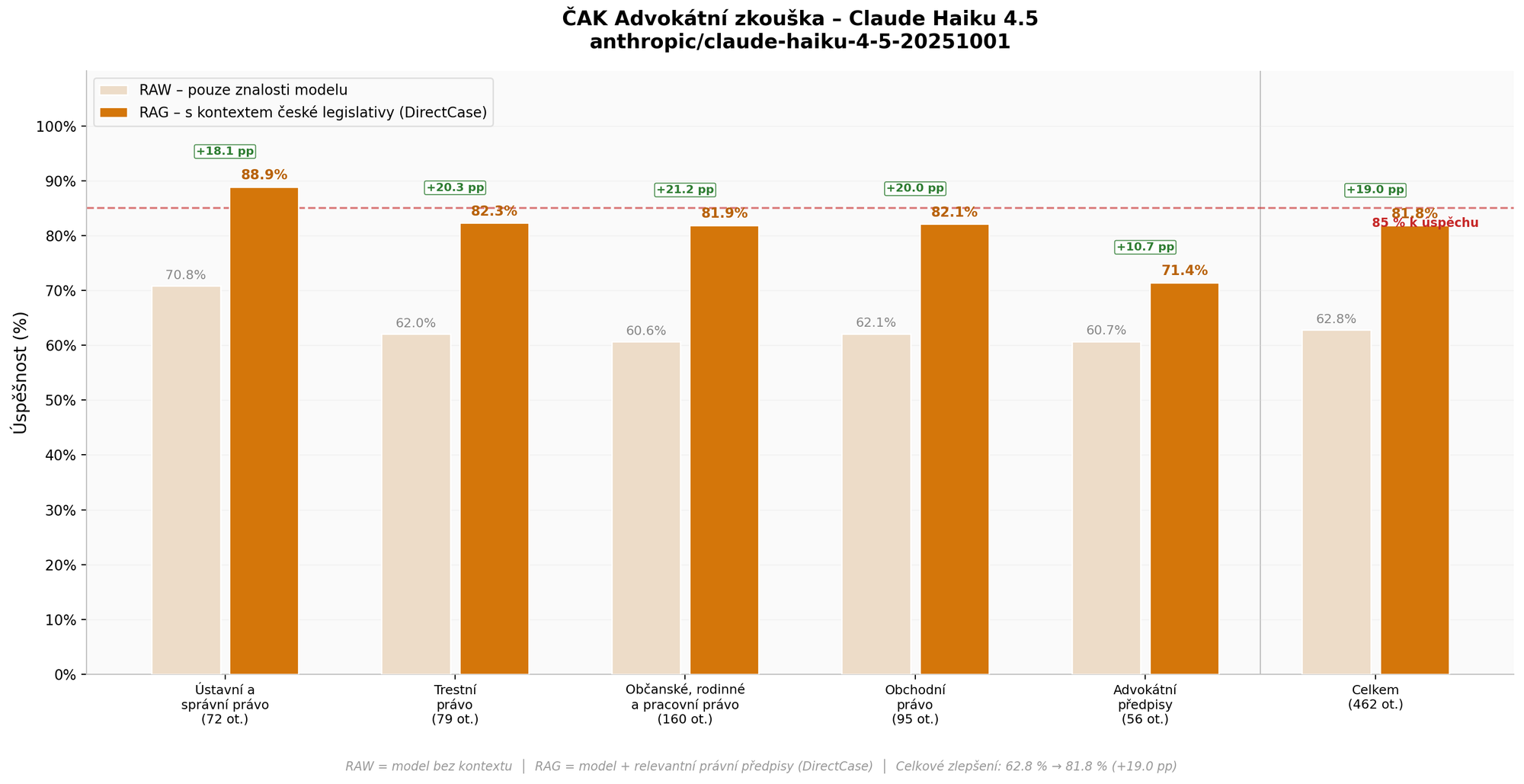
Claude Haiku 4.5 (Anthropic)

| Okruh | RAW | RAG | Zlepšení |
|---|---|---|---|
| Ústavní a správní právo | 70,8 % (51/72) | 88,9 % (64/72) | +18,1 pp |
| Trestní právo | 62,0 % (49/79) | 82,3 % (65/79) | +20,3 pp |
| Občanské, rodinné a pracovní právo | 60,6 % (97/160) | 81,9 % (131/160) | +21,2 pp |
| Obchodní právo | 62,1 % (59/95) | 82,1 % (78/95) | +20,0 pp |
| Advokátní předpisy | 60,7 % (34/56) | 71,4 % (40/56) | +10,7 pp |
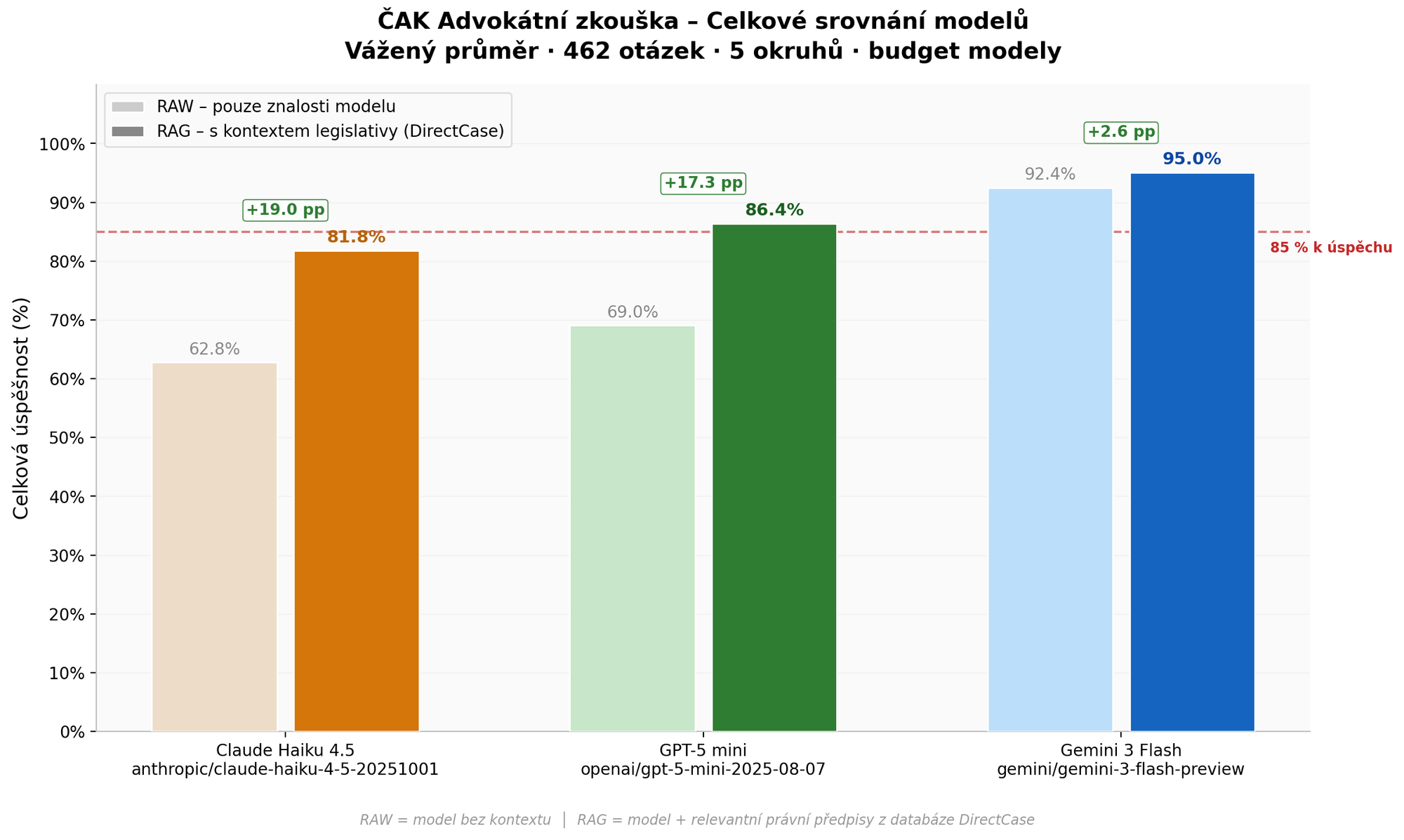
| Celkem (vážený průměr) | 62,8 % (290/462) | 81,8 % (378/462) | +19,0 pp |
Claude Haiku 4.5 dosáhl v režimu RAW celkové úspěšnosti pouhých 62,8 %, což je daleko pod hranicí úspěšného složení zkoušky. S přístupem k legislativě (RAG) se úspěšnost zvýšila na 81,8 % – výrazné zlepšení o 19 procentních bodů, avšak stále pod hranicí 85 %. Jediný okruh, kde model s RAG překonal hranici úspěšnosti, je ústavní a správní právo (88,9 %).
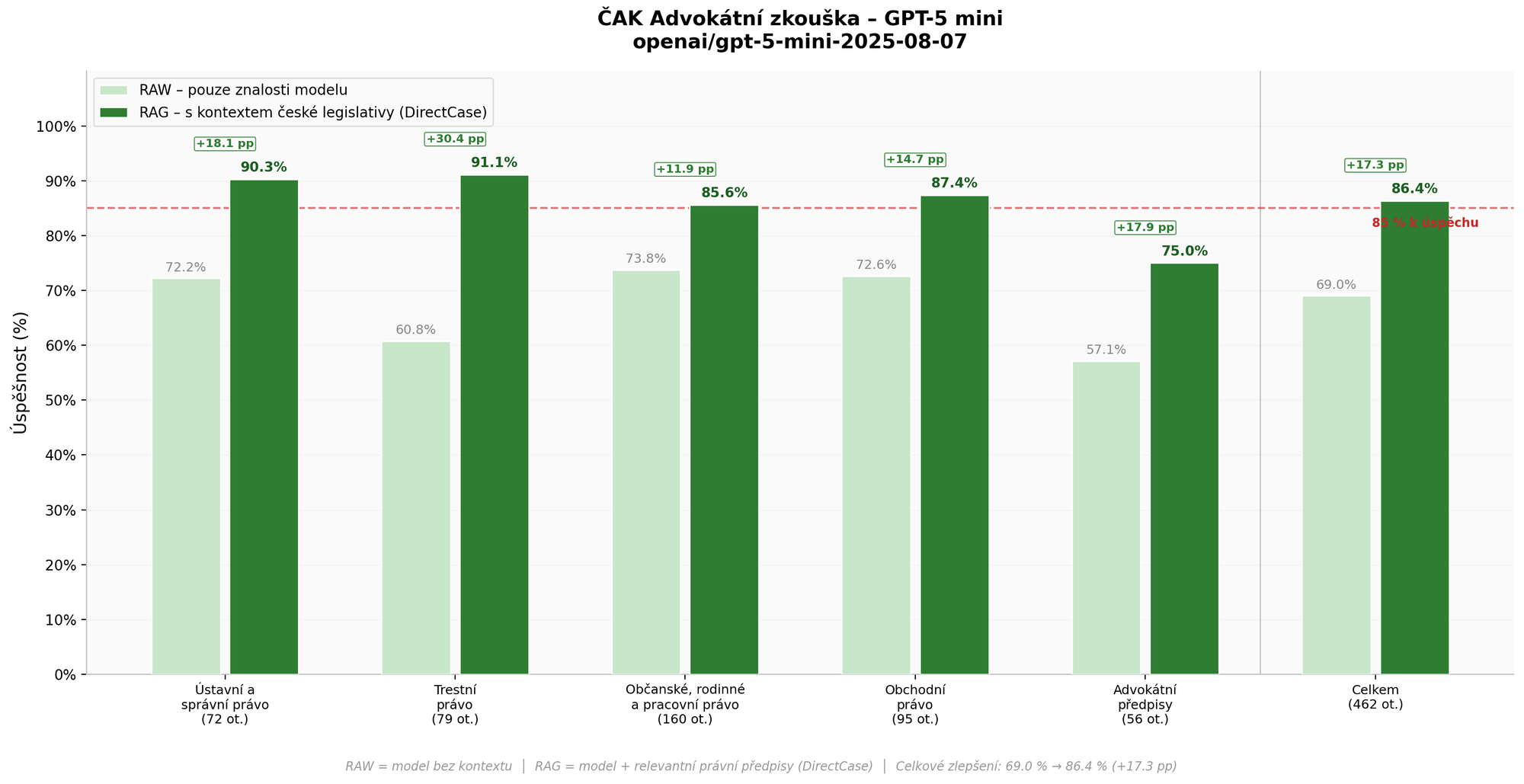
GPT-5 mini (OpenAI)

| Okruh | RAW | RAG | Zlepšení |
|---|---|---|---|
| Ústavní a správní právo | 72,2 % (52/72) | 90,3 % (65/72) | +18,1 pp |
| Trestní právo | 60,8 % (48/79) | 91,1 % (72/79) | +30,4 pp |
| Občanské, rodinné a pracovní právo | 73,8 % (118/160) | 85,6 % (137/160) | +11,9 pp |
| Obchodní právo | 72,6 % (69/95) | 87,4 % (83/95) | +14,7 pp |
| Advokátní předpisy | 57,1 % (32/56) | 75,0 % (42/56) | +17,9 pp |
| Celkem (vážený průměr) | 69,0 % (319/462) | 86,4 % (399/462) | +17,3 pp |
GPT-5 mini v režimu RAW dosáhl 69,0 % – lepší než Claude Haiku, ale stále nedostatečné. S RAG se úspěšnost vyšplhala na 86,4 %, čímž model jako jediný z testované trojice překročil hranici 85 % potřebnou ke složení zkoušky. Mimořádně výrazné je zlepšení v trestním právu (+30,4 pp), kde se model z 60,8 % dostal na 91,1 %. Slabinou zůstávají advokátní předpisy (75,0 % i s RAG).
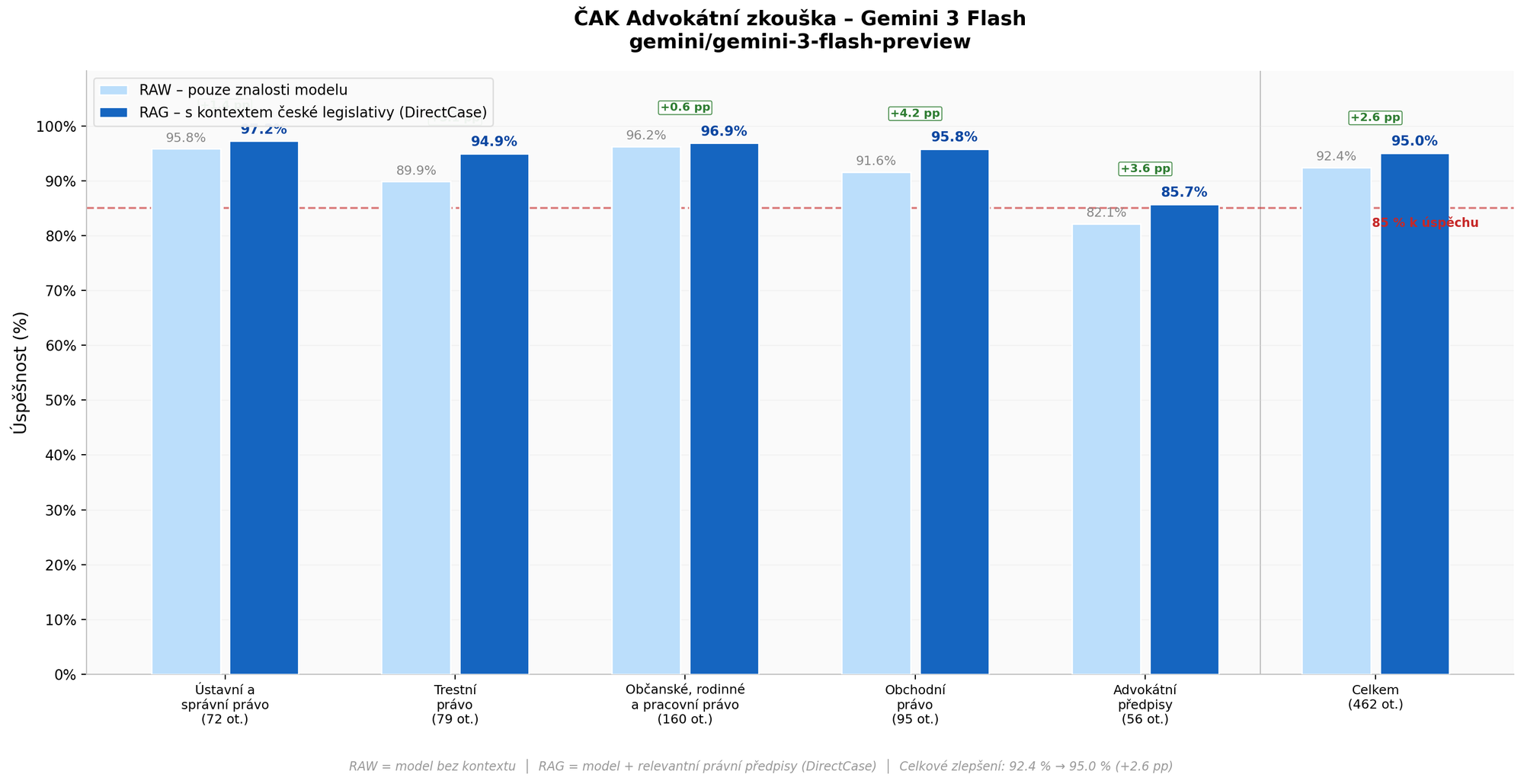
Gemini 3 Flash (Google)

| Okruh | RAW | RAG | Zlepšení |
|---|---|---|---|
| Ústavní a správní právo | 95,8 % (69/72) | 97,2 % (70/72) | +1,4 pp |
| Trestní právo | 89,9 % (71/79) | 94,9 % (75/79) | +5,1 pp |
| Občanské, rodinné a pracovní právo | 96,2 % (154/160) | 96,9 % (155/160) | +0,6 pp |
| Obchodní právo | 91,6 % (87/95) | 95,8 % (91/95) | +4,2 pp |
| Advokátní předpisy | 82,1 % (46/56) | 85,7 % (48/56) | +3,6 pp |
| Celkem (vážený průměr) | 92,4 % (427/462) | 95,0 % (439/462) | +2,6 pp |
Gemini 3 Flash vykazuje výrazně odlišný profil. Již v režimu RAW dosahuje celkové úspěšnosti 92,4 % a úspěšně by složil advokátní zkoušku i bez jakéhokoliv externího kontextu. RAG přinesl další zlepšení na 95,0 %, ale přírůstek je jen +2,6 pp – výrazně méně než u ostatních modelů. Jedinou slabinou v RAW režimu byly advokátní předpisy (82,1 %), které RAG pomohl překonat na 85,7 %.
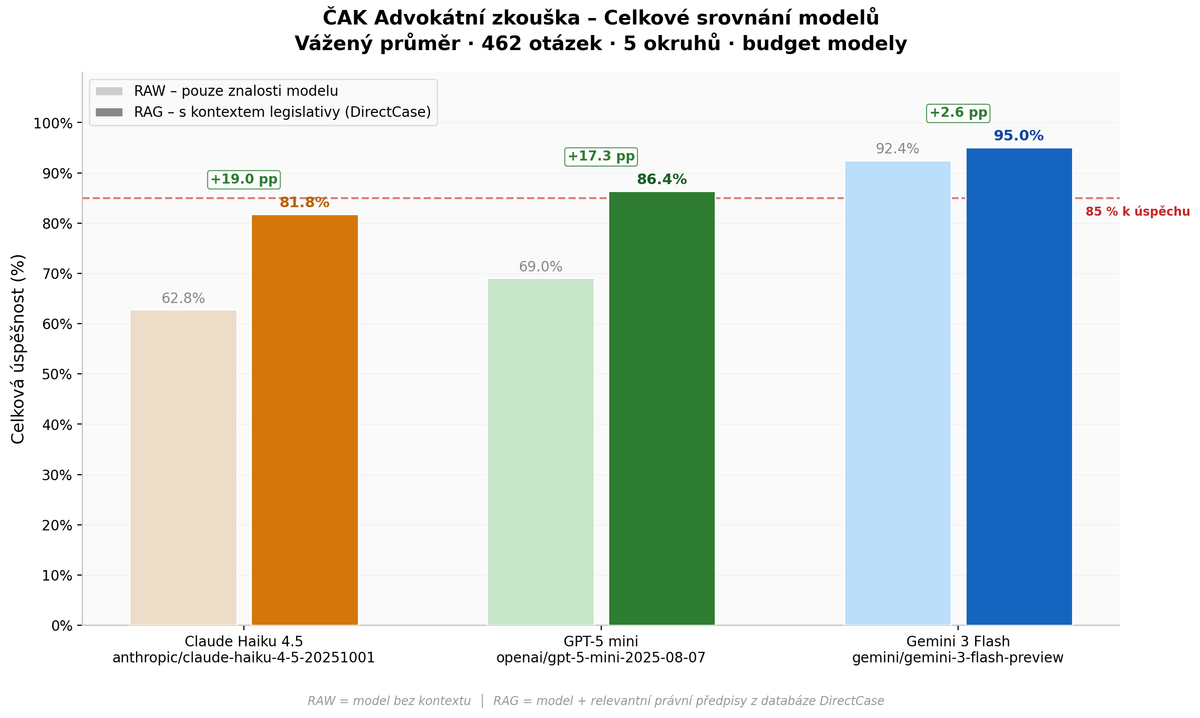
Celkové srovnání

| Model | RAW | RAG | Zlepšení | Složil by zkoušku? |
|---|---|---|---|---|
| Claude Haiku 4.5 | 62,8 % | 81,8 % | +19,0 pp | Ne (ani s RAG) |
| GPT-5 mini | 69,0 % | 86,4 % | +17,3 pp | Ano (s RAG) |
| Gemini 3 Flash | 92,4 % | 95,0 % | +2,6 pp | Ano (i bez RAG) |
Průměrná doba odpovědi
| Model | RAW | RAG |
|---|---|---|
| Claude Haiku 4.5 | ~2,3 s | ~10,9 s |
| GPT-5 mini | ~14,5 s | ~16,2 s |
| Gemini 3 Flash | ~4,6 s | ~15,9 s |
Režim RAG je přirozeně pomalejší, protože zahrnuje vyhledávání relevantních dokumentů v právní databázi. U Claude Haiku je rozdíl nejvýraznější (z 2,3 s na 10,9 s), zatímco u GPT-5 mini je nárůst relativně mírný (z 14,5 s na 16,2 s).
Analýza a diskuse
Vliv RAG na výkon
Výsledky jasně ukazují, že RAG má zásadní pozitivní vliv na výkon budget modelů v právním testování:
- Claude Haiku 4.5 – zlepšení o 19,0 pp, ale stále nedosahuje hranice úspěšnosti
- GPT-5 mini – zlepšení o 17,3 pp, s RAG překračuje hranici 85 %
- Gemini 3 Flash – zlepšení pouze o 2,6 pp, ale výchozí úroveň je již velmi vysoká
U modelů s nízkou výchozí úspěšností (Claude Haiku, GPT-5 mini) RAG přinesl konzistentní zlepšení přes všechny okruhy – typicky o 10–30 procentních bodů. To potvrzuje, že přístup k ověřeným právním pramenům je pro tyto modely klíčový.
Advokátní předpisy jako nejslabší okruh
Napříč všemi modely je okruh advokátní předpisy konzistentně nejslabší – a to jak v RAW, tak v RAG režimu. Tato oblast zahrnuje pravidla specifická pro výkon advokacie (etika, stavovské předpisy, tarify), která jsou méně zastoupena v trénovacích datech i v obecné legislativě.
Poměr cena/výkon
Zajímavé je srovnání z hlediska ceny:
- GPT-5 mini ($0,25 vstup / $2,00 výstup za 1M tokenů) s RAG složí zkoušku za zlomek ceny
- Claude Haiku 4.5 ($1,00 / $5,00) ani s RAG nestačí
- Gemini 3 Flash ($0,50 / $3,00) zvládá zkoušku i bez RAG, ale jeho výsledky vyvolávají metodologické otázky (viz níže)
Metodologické upozornění
Je nutné upozornit na zásadní metodologické omezení tohoto benchmarku. Otázky z advokátních zkoušek ČAK jsou dostupné na veřejných webových stránkách (např. advokat.etesty.cz) a mohou být součástí trénovacích dat jazykových modelů.
Model s úspěšností blízkou 100 % v režimu RAW může být podezřelý z toho, že byl trénován na datech obsahujících právě tyto testovací otázky. V takovém případě nedochází k měření skutečných znalostí či schopnosti právního uvažování modelu, ale pouze k reprodukci zapamatovaných odpovědí. Jedná se o zásadní metodologickou chybu známou jako „data contamination" (kontaminace trénovacích dat).
Konkrétně Gemini 3 Flash, který dosahuje 92,4 % v RAW režimu s úspěšností přes 95 % v několika okruzích, vykazuje znaky možné kontaminace. Pro srovnání – ostatní modely v RAW režimu dosahují 62–69 %, což lépe odpovídá očekávanému výkonu modelu bez specifických znalostí českého práva.
Doporučení pro budoucí benchmarky
Pro důvěryhodné hodnocení právních schopností AI modelů by bylo vhodné:
- Vytváření neveřejných benchmarků – otázky by neměly být veřejně přístupné na internetu
- Spolupráce s odbornými institucemi – benchmarky by měly vytvářet právnické fakulty a odborné instituce, nikoliv čerpat z veřejně dostupných zdrojů
- Pravidelná obměna otázek – aby se předešlo postupné kontaminaci trénovacích dat
- Transparentní publikace výsledků – pravidelné srovnávací studie od nezávislých institucí
- Kontrola kontaminace – testování, zda model dokáže reprodukovat přesné znění otázek (což by nasvědčovalo memorování)
Bez těchto opatření hrozí, že benchmarky budou měřit spíše míru zapamatování testových otázek než skutečnou schopnost právního uvažování.
Závěr
Výzkum ukázal, že technologie RAG s přístupem k databázi DirectCase přináší výrazné zlepšení výkonu budget AI modelů na advokátní zkoušce ČAK:
- U modelů s nízkou výchozí úspěšností RAG konzistentně zlepšuje výkon o 17–19 procentních bodů
- GPT-5 mini s RAG jako jediný budget model překročil hranici 85 % potřebnou ke složení zkoušky
- Přístup k aktuální legislativě je klíčový zejména pro modely, které nemají české právo dostatečně zastoupeno v trénovacích datech
- Výsledky modelů s extrémně vysokou RAW úspěšností je třeba interpretovat opatrně kvůli možné kontaminaci trénovacích dat
Tyto výsledky naznačují, že kombinace cenově dostupného AI modelu s kvalitní právní databází může být prakticky využitelná pro podporu právní praxe – nikoliv jako náhrada advokáta, ale jako efektivní nástroj pro rychlou orientaci v právních předpisech.
Benchmark proveden v březnu 2026. Zdrojem otázek je web advokat.etesty.cz. Upozorňujeme, že web etesty neobsahuje všechny otázky z advokátních zkoušek. Právní databáze DirectCase poskytuje přístup k české a evropské legislativě, judikatuře a rozhodovací praxi regulatorních orgánů.